Executing an
unconditional branch instruction
using the modified
ID stage
|
Executing an
unconditional
branch instruction using the
modified ID stage
- Example
Start of cycle 1: IF stage is fetching the branch instruction:
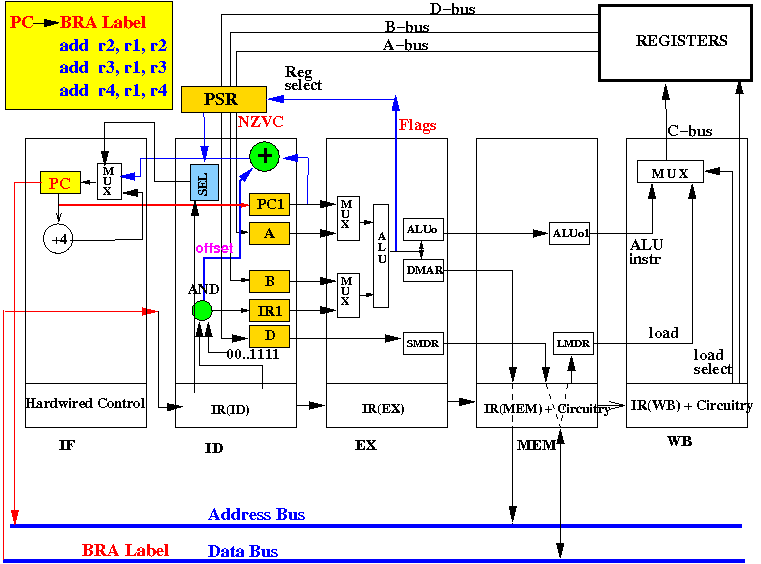
Executing an
unconditional
branch instruction using the
modified ID stage
- Example
End of cycle 1: BRA Lable is fetched in IR(ID)
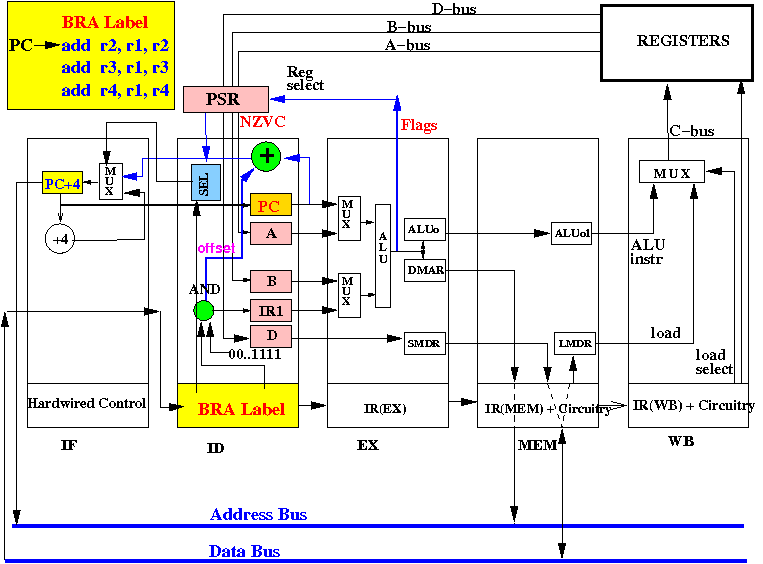
Because we always make a copy of the PC into the ID stage, the value of PC available as source operand !
Executing an
unconditional
branch instruction using the
modified ID stage
- Example
Start of cycle 2: ID stage computes PC + offset, IF stage fetches add r2,r1,r2:
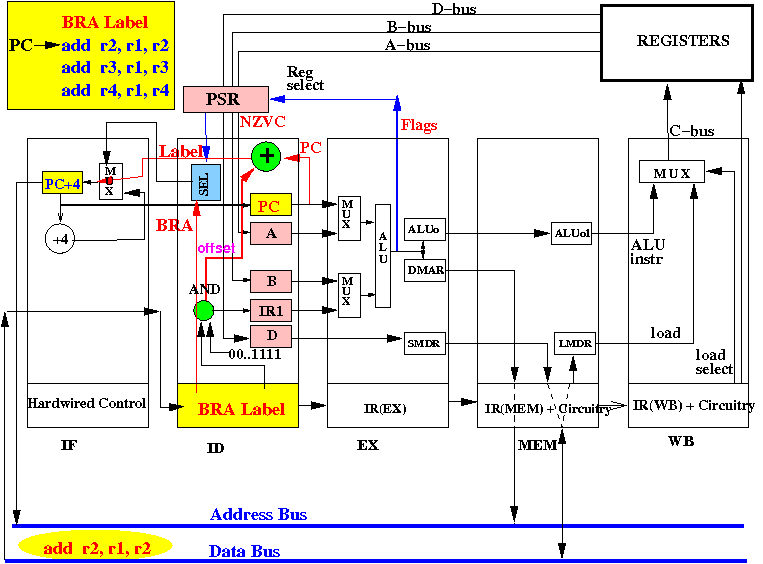
The MUX will always select PC + offset (= Label) as input when executing an unconditional branch instruction
Executing an
unconditional
branch instruction using the
modified ID stage
- Example
End of cycle 2: PC is updated to address Label , add r2,r1,r2 is fetched in IR(ID)
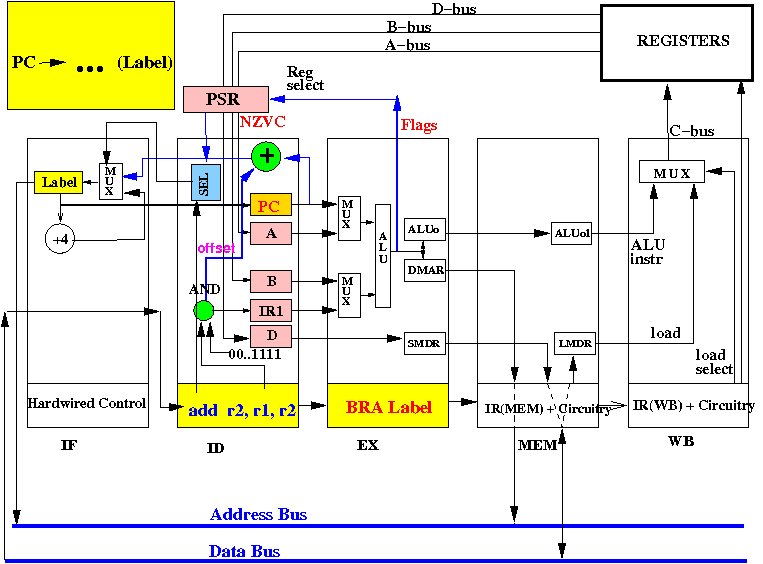
The CPU made the branch in 2 clock periods !! There was a one-instruction branch delay...
DEMO (using Aaron's pipelined CPU)
|
Demo: delayed branching
in a real (SPARC) CPU
|