- Speedup (speedier execution) is achieved by executing
multiple instructions simulataneously
- Consider the execution of the following sequence of ALU instructions
by the basic pipelined CPU:
add r1, r2, r3 add r1, r4, r5 add r1, r6, r7 add r1, r3, r5 ...
- The following sequence of figures shows how the Pipelined CPU can process multiple instructions simultaneously...
Slideshow:
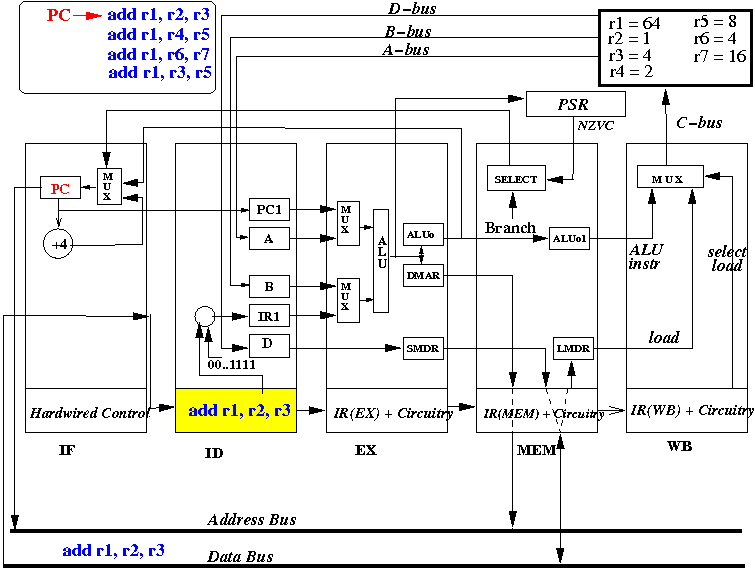
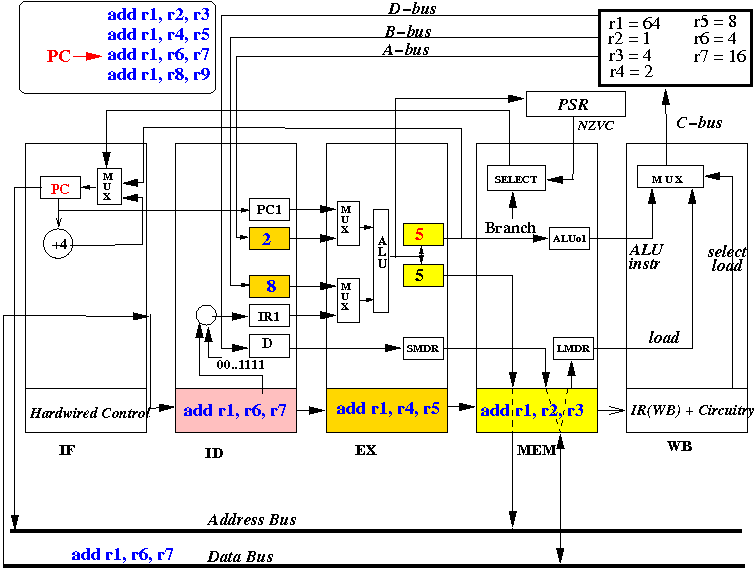

- At start of the CPU cycle, the IF stage sends out PC
- At end of the CPU cycle, the IR(ID) register is updated with
the instruction fetched (add r1, r2, r3)
- The picture above depicts the content of the CPU at end of the first CPU cycle (and the start of the 2nd cycle)
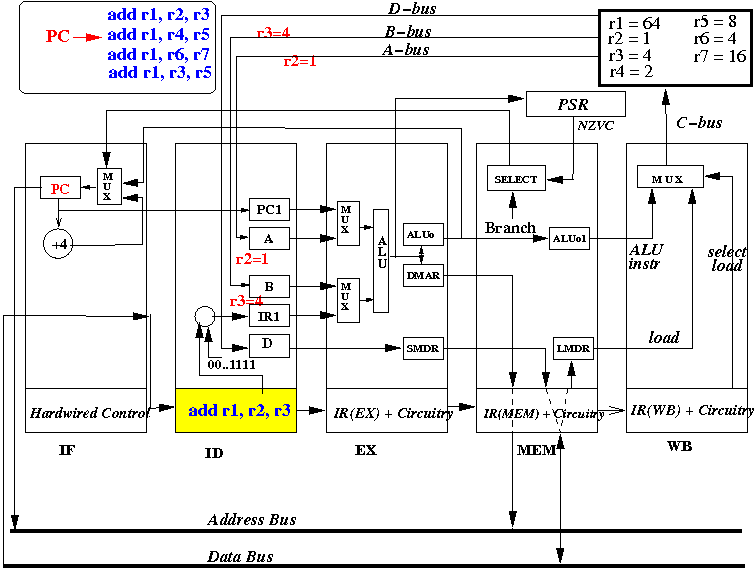
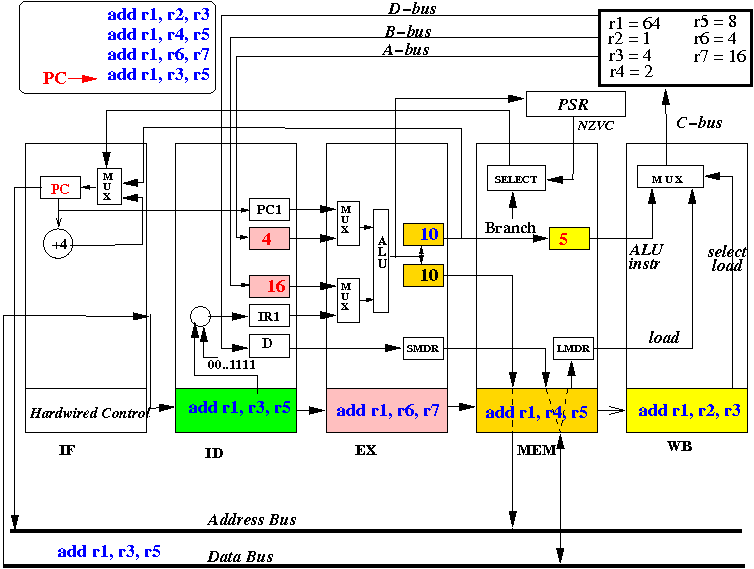
- At start of the CPU cycle, the ID stage sends out selection signal that selects the values from R2 (=first source operand) and R3 (=second source operand).
- At end of the CPU cycle, the "A" register is updated with R2 = 1,
and the "B" register is updated with R3= 4.
- Also, at the end of the CPU cycle, the
instruction (add r1, r2, r3) is
moved into IR(EX) and next instruction
"add r1, r4, r5" is fetched
into IR(ID)
- The picture above depicts the content of the CPU at end of the second CPU cycle (and the start of the 3rd cycle)
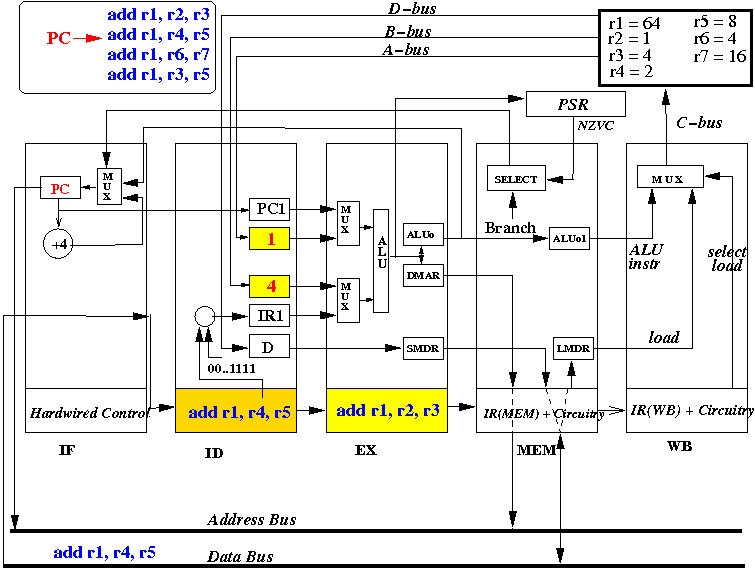
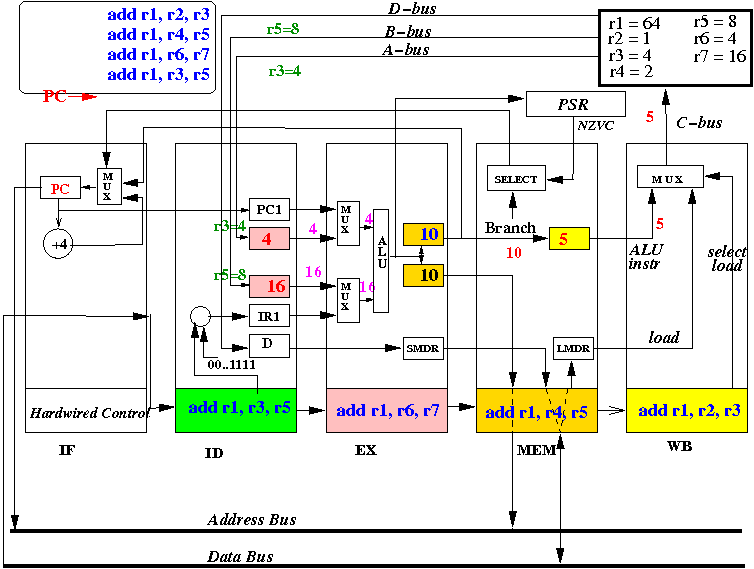
- At start of the CPU cycle, the EX stage selects
values from the "A" register (=R2=1) and
the "B" register (=R3=4) for the ALU input, use the ALU opcode (add)
to make ALU add the input values
Also, at start of the CPU cycle, the ID stage selects R4 and R5 to be copied into the "A" and "B" registers.
- At end of the CPU cycle, ALUo and DMAR registers is updated with
the value R1+R2 = 5.
Also, at the end of the CPU cycle, the "A" register is updated to the value in R4 and the "B" register is updated to the value in R5.
Also, at the end of the CPU cycle, the instruction (add r1, r2, r3) is moved into IR(MEM), "add r1, r4, r5" is moved into IR(EX) and instruction "add r1, r6, r7" is fetched into IR(ID):
- The picture above depicts the content of the CPU at end of the 3rd CPU cycle (and the start of the 4th cycle)
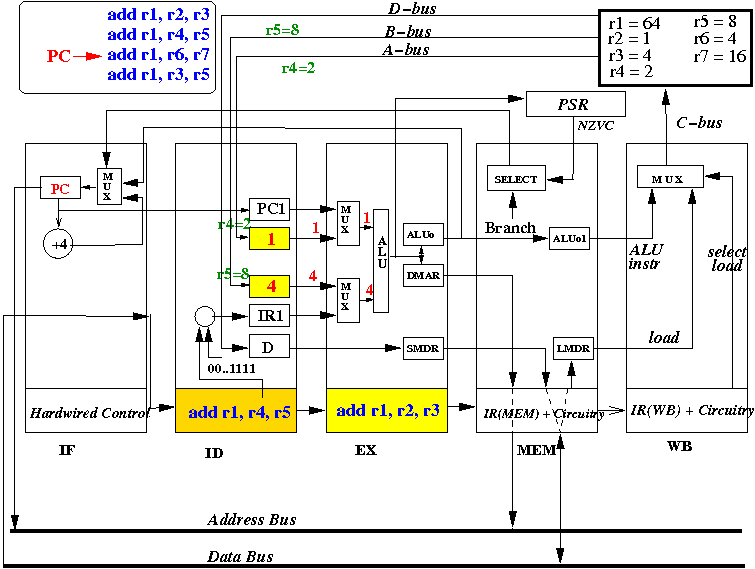
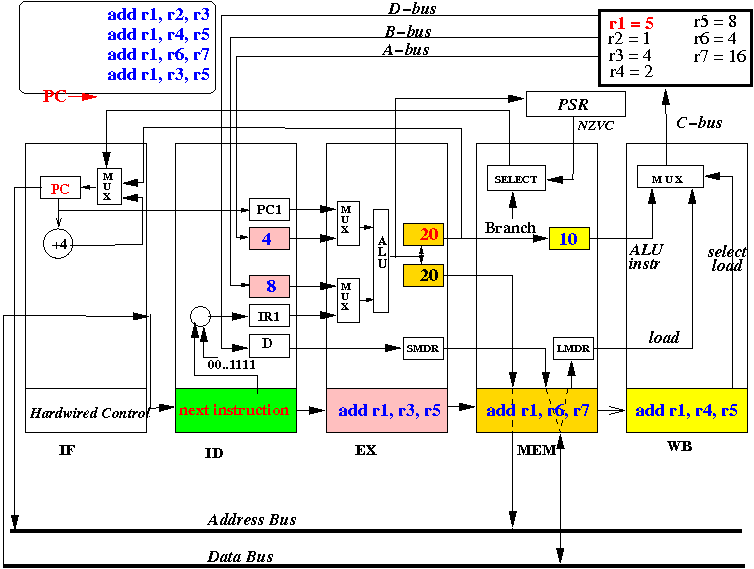
- At start of the CPU cycle, the MEM stage's ALUo1
register will start to receive the output of
"add r1, r2, r3".
- Also at start of the CPU cycle, the EX stage selects
values from the "A" register (=R4=2) and
the "B" register (=R5=8) for the input of the ALU, and
use the ALU opcode (00 = add)
to make ALU add the input values
Also, at start of the CPU cycle, the ID stage selects registers R6 and R7 to be copied into the "A" and "B" registers.
- At end of the CPU cycle, ALUo1 in MEM stage is updated with
the value R2+R3 = 5
- Also, at end of the CPU cycle, ALUo and DMAR registers is updated with
the value R4+R5 = 10
Also, at the end of the CPU cycle, the "A" register is updated to R6 and the "B" register is updated to R7.
Also, at the end of the CPU cycle, the instruction (add r1, r2, r3) is moved into IR(WB), "add r1, r4, r5" is moved into IR(MEM), instruction "add r1, r6, r7" is moved into IR(EX) and instruction "add r1, r3, r5" is fetched into IR(ID):
- The picture above depicts the content of the CPU at end of the 4th CPU cycle (and the start of the 4th cycle)
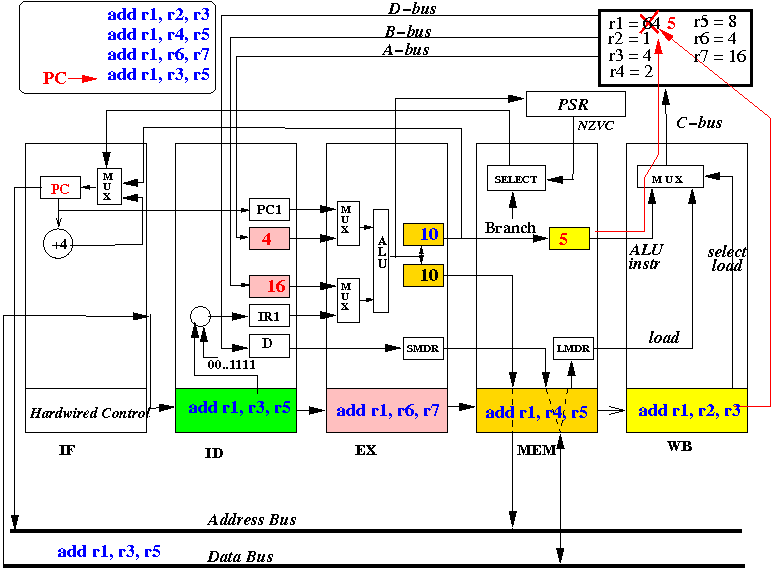
And advances to the following state:
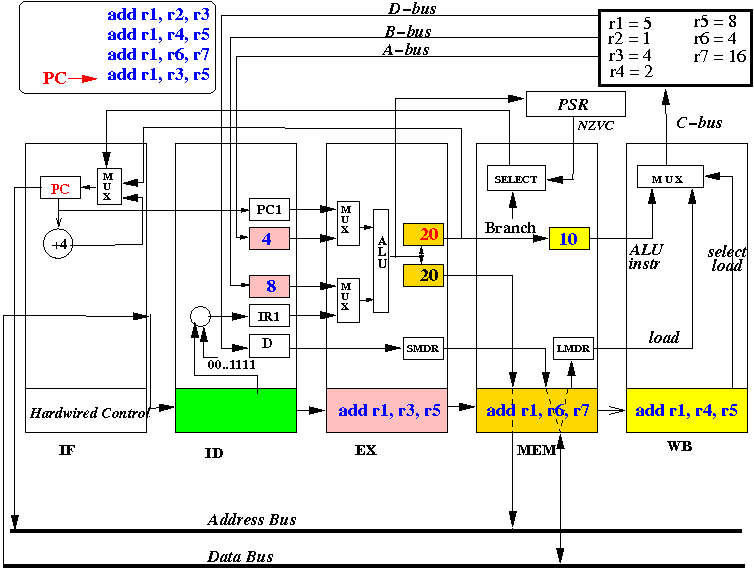
Then in the following cycle the next cycle, the instruction "add r1, r4, r5", will update R1 with R4+R5=10:
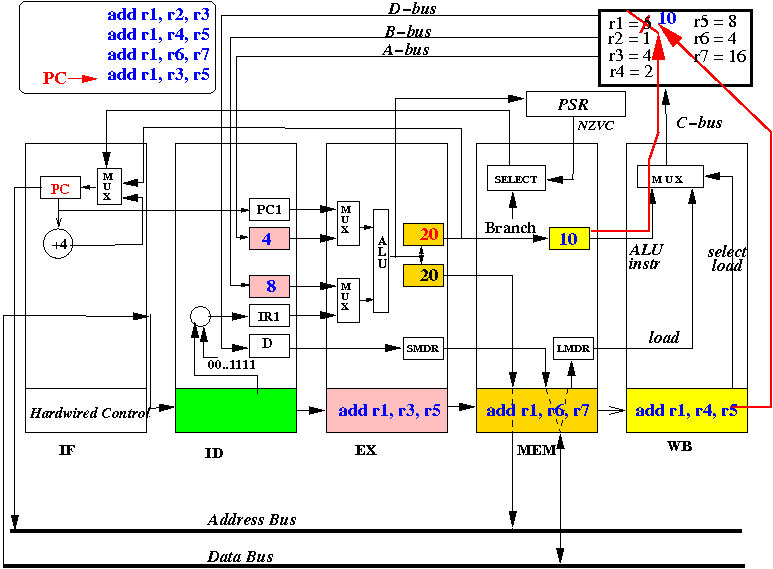
And so on !!!
So the execution of every instruction will be correct even these instructions are processed simultaneously !!!
Well, not quite... we will find some problems in the basic pipelined CPU later....
But before we find fault on the basic pipelined CPU, let's look at how the basic pipelined CPU execute the other types of instructions (Load, Store, Branch)...

/home/cs355001/demo/pipeline/1c-ALU-speedup
Executes:
10 64 // mov r1, #64
18 1 // mov r2, #1
26 4 // mov r3, #4
34 2 // mov r4, #2
42 8 // mov r5, #8
50 4 // mov r6, #4
58 16 // mov r7, #16
0 0 // nop
0 0 // nop
0 0 // nop
0 0 // nop
0 0 // nop
8 19 // add r1,r2,r3 (R1=R2+R3)
8 37 // add r1,r4,r5 (R1=R4+R5)
8 55 // add r1,r6,r7 (R1=R6+R7)
|