- Note:
- ⋈ is the
natural join operator
- This material is valid for any join operation using = as join condition
- ⋈ is the
natural join operator
- Requirement:
R = (X, Y) S = (Y, Z) S has an index on Y
- Algorithm for
R ⋈ S using index
S.Y:
while ( R has data blocks ) { read a block of R in b; for ( each tuple tr ∈ b ) do { Use tr(Y) to lookup in index S.Y; // You get a list of record addresses for ( each record address s ) do { read tuple at s; output tr, ts; // Join result } } }
- The join algorithm
will scan the
relation R once.
- For each tuple
tr ∈ R,
we read the
following portion in
relation S:
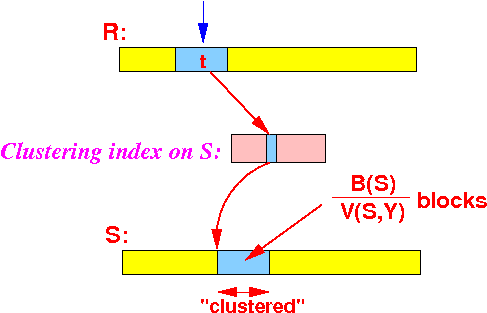
- The portion of
relation S
consists of this number of blocks:
B(S) portion of S read per tuple of R = -------- blocks V(S,Y)because:
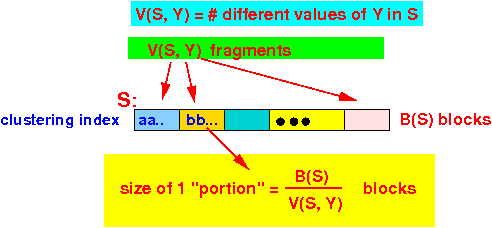
- # disk IO used in
join algorithm with
an clustering index:
Index Join algorith using a clustering index: # disk IOs = Scan R once + # tuples in R × # blocks of S read per tuple of R B(S) = B(R) + T(R) × -------- V(S,Y)
Since T(R) >> B(R), we can approximate: B(S) # disk IOs ~= T(R) × ------- V(S,Y)
- Note:
- We have assumed that
relation R is
clustered
- If relation R is
not clustered, then
scanning R will
cost:
T(R) blocks disk/IO (instead of B(R) blocks)
- The cost of the join if
R is
not clustered is then:
B(S) # disk IOs for non-clustered R = T(R) + T(R) × -------- V(S,Y) B(S) ~= T(R) + -------- (unchanged !) V(S,Y)
- We have assumed that
relation R is
clustered
- The join algorithm
will scan the
relation R once.
- For each tuple
tr ∈ R,
we read the
following portion in
relation S:
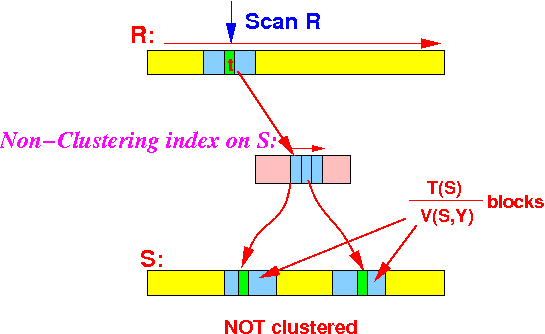
- The portion of
relation S
consists of this number of blocks:
T(S) portion of S read per tuple of R = -------- blocks V(S,Y)because:
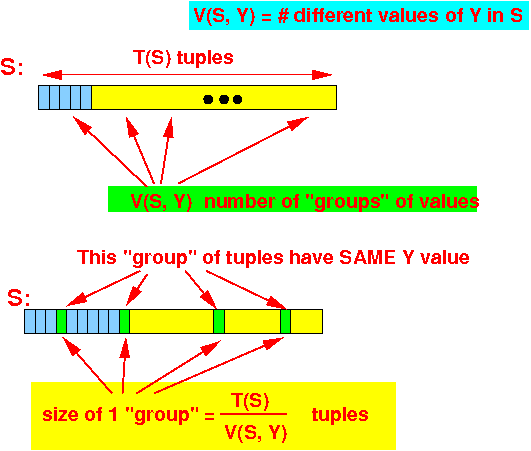
- # disk IO used in
join algorithm with
an NON-clustering index:
Index Join algorith using a clustering index: # disk IOs = Scan R once + # tuples in R × # blocks of S read per tuple of R T(S) = B(R) + T(R) × -------- (assuming different tuples V(S,Y) are located in diff. blocks)
Since T(R) >> B(R), we can approximate: T(S) # disk IOs ~= T(R) × ------- V(S,Y)
- Note:
- We have assumed that
relation R is
clustered
- If relation R is
not clustered, then
scanning R will
cost:
T(R) blocks disk/IO (instead of B(R) blocks)
- The cost of the join if
R is
not clustered is then:
T(S) # disk IOs for non-clustered R = T(R) + T(R) × -------- V(S,Y) T(S) ~= -------- (unchanged !) V(S,Y)
- We have assumed that
relation R is
clustered
- Consider the following
scenario 1:
(large relation R)
relation R(X,Y) relation S(Y,Z) -------------------------------------------- B(R) = 1000 blks B(S) = 500 blocks T(R) = 10000 tuples T(S) = 5000 tuples V(S,Y) = 100
- Assuming that:
- There is a clustering index on Y of relation S
# disk IO used by the index Join algorithm:
B(S) # disk IO ~= T(R) × ------- V(S,Y) 500 = 10000 × ------ 100 = 50,000 blocks# disk IO used by the one-pass join algorithm
# disk IO = B(R) + B(S) (See: click here) = 1000 + 500 = 1500 blocks
- $64,000 question:
- Looks like
the one-pass algorithm is
much better than
the index-join algorithm !!!
- Why bother to
study this algorithm ????
- Index-join is in fact
very useful
in SQL query processing
See the next scenario !!!
- Index-join is in fact
very useful
in SQL query processing
- Looks like
the one-pass algorithm is
much better than
the index-join algorithm !!!
- Consider the following
scenario 2:
(tiny relation R)
relation R(X,Y) relation S(Y,Z) -------------------------------------------- B(R) = 1 blks B(S) = 500 blocks T(R) = 10 tuples T(S) = 5000 tuples V(S,Y) = 100
- Assuming that:
- There is a clustering index on Y of relation S
# disk IO used by the index Join algorithm:
B(S) # disk IO ~= T(R) × ------- V(S,Y) 500 = 10 × ------ 100 = 50 blocks# disk IO used by the one-pass join algorithm based on TPMMS
# disk IO = B(R) + B(S) (See: click here) = 1 + 500 = 501 blocks
- General guideline:
- Index-join algorithm
is used when
one of the
relations in the
join is
very small
and
- There is an index on the join attribute(s) in the other (large) relation
- Index-join algorithm
is used when
one of the
relations in the
join is
very small
and
- Note:
- The very small relation
used in an
index-join algorithm
is often:
- The result relation of a selection operation
- Example:
σsalary > 50000 (employee) ⋈ department R = σsalary > 50000 (employee) is a very small relation !!!
- The very small relation
used in an
index-join algorithm
is often: