Slideshow:
Example on selection implementation algorithm for a query plan -
materialization
Problem description:

Find the best algorithm to execute ⋈1 and ⋈2 for M = 101 - click to pull out
Example on selection implementation algorithm for a query plan -
materialization
Simplified Problem :
Solution method: brute force search for the min. cost algorithms that can operate with M = 101
Example on selection implementation algorithm for a query plan -
materialization
Step 1: check if we can use a 1-pass algorithm for ⋈1:

Example on selection implementation algorithm for a query plan -
materialization
Step 2: check if we can use a 2-pass (hashing based) algorithm for ⋈1:

Next, we find the best algorithm for ⋈2 (considering the buffer utilization of ⋈1 !)
Example on selection implementation algorithm for a query plan -
materialization
Determining the buffer utilization by the ⋈1 execution:
(⋈2 is inactive and will not use any buffers)
Example on selection implementation algorithm for a query plan -
materialization
Determining the buffer utilization by the ⋈1 execution:
Next: we run pass 2 of the 2-pass (hashing-based) algorithm (= a 1-pass algorithm on each Ri and Si)
Example on selection implementation algorithm for a query plan -
materialization
Determining the buffer utilization by the ⋈1 execution:
Note: pass 2 is run for every chunk Ri and Si and pass 2 will write tuples to disk (materialize !)
Example on selection implementation algorithm for a query plan -
materialization
Cost (so far):
Click on image to pull out (keep running cost)
Next: determine the best suitable join algorithm for ⋈2
Example on selection implementation algorithm for a query plan -
materialization
Prelude to considering the implementation algorithm for ⋈2:
⋈1 has written its output tuples to disk:
I.e.: we must find the best algorithm for ⋈2 using M = 101 buffers !!
Example on selection implementation algorithm for a query plan -
materialization
Step 3: check if we can use a 1-pass algorithm for ⋈2:
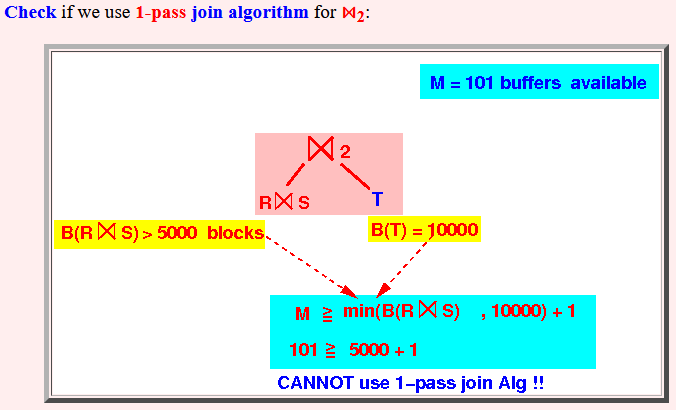
Therefore: we cannot use the 1-pass join algorithm
Example on selection implementation algorithm for a query plan -
materialization
Step 4: check if we can use a 2-pass (hashing based) algorithm for ⋈2:
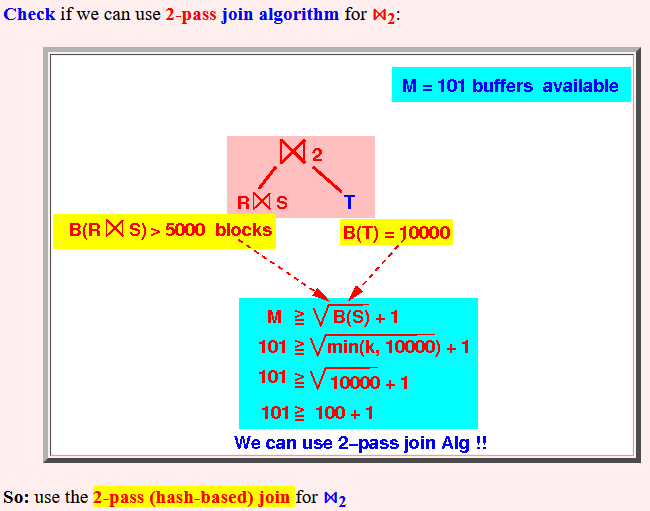
Note: because B(T) = 10,000 blks, we can always use the 2-pass (hash) join algorithm - regardless of the value of B(R⋈S) !
Example on selection implementation algorithm for a query plan -
materialization
Cost analysis:

- We consider the
execution
for
the following
logical query plan
using materialization
of R⋈S:
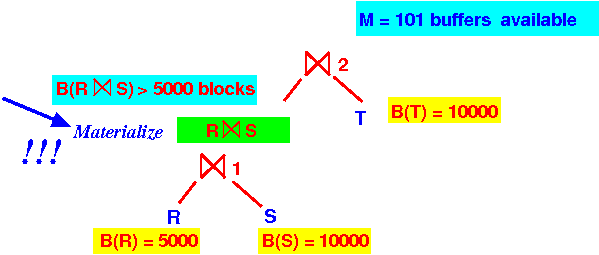
Relevant statistics:
- B(R) = 5000 blocks - clustered, no index on R
- B(S) = 10000 blocks - clustered, no index on S
- B(T) = 10000 blocks
-
clustered,
no index
on T
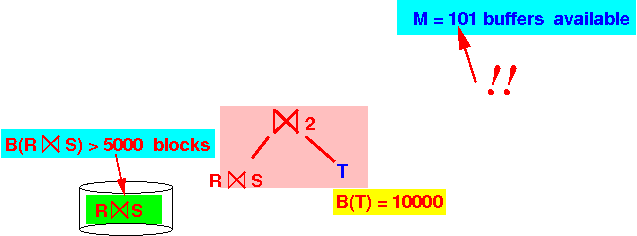
- B(R ⋈ S) > 5000 blocks
- The result of
R ⋈ S is
materialized on
disk
(⋈2 reads the tuple(s) from R ⋈ S off of the disk)
- The result of
R ⋈ S is
materialized on
disk
- Available buffers = 101 blocks
- Choice
for the join algorithm:
- One-pass join algorithm (see: click here)
- 2-pass join algorithm based on hashing (see: click here)
- 3-pass join algorithm based on hashing (see: click here)
- Problem:
- Determine
the minimum cost algorithm
you can use for
⋈1 and
⋈2
- Determine the total # disk IOs incurred by the physical query plan
- Determine
the minimum cost algorithm
you can use for
⋈1 and
⋈2
- Step 1:
check if
we can use a 1-pass algorithm
for ⋈1:
-
We have performed this
check
before:
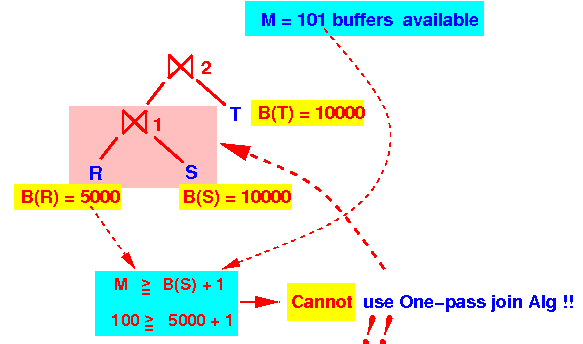
Since:
M = 101 < 5001We cannot use a 1-pass algorithm for ⋈1
-
We have performed this
check
before:
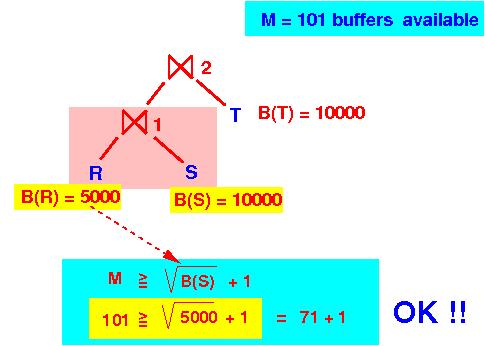
- Step 2:
check if we can use
a
2-pass (hashing based)
join algorithm for
⋈2
-
We have performed this
check
before:
How is the ⋈1 executed:
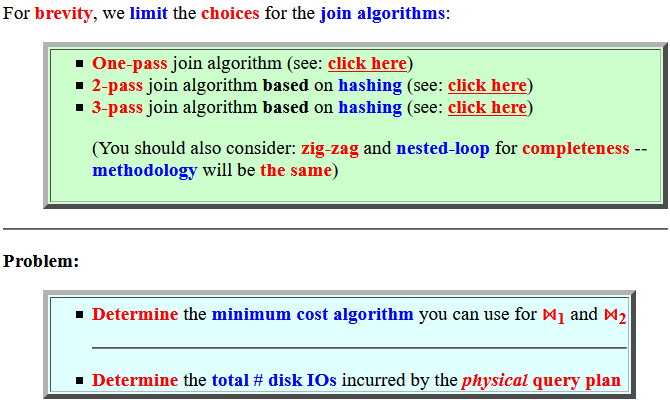
Pass 1 of the 2-pass hash join alg: (1) We use 101 buffer to hash R into 100 sub-relations Ri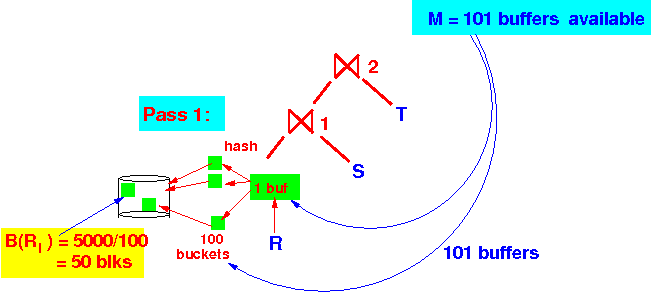 (2) Use 101 buffer to hash S into 100 sub-relations Si
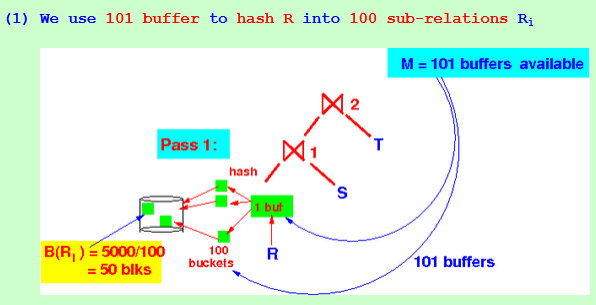
(2) Use 101 buffer to hash S into 100 sub-relations Si
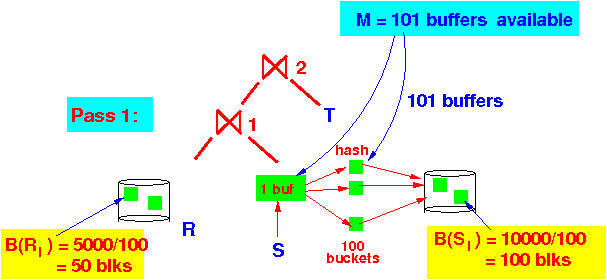 Assuming uniform distribution:
B(Ri) = 5000/100 = 50 blocks (smaller)
B(Si) = 10000/100 = 100 blocks
Assuming uniform distribution:
B(Ri) = 5000/100 = 50 blocks (smaller)
B(Si) = 10000/100 = 100 blocks
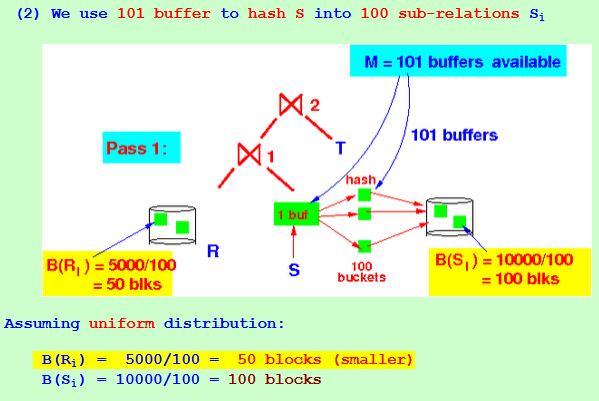
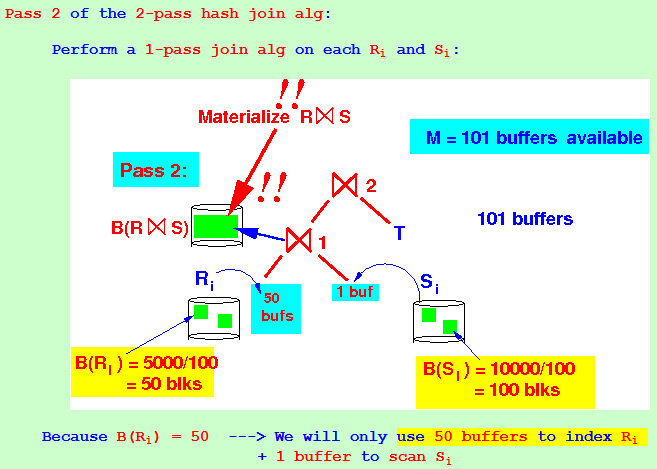
Pass 2 of the 2-pass hash join alg: Perform a 1-pass join alg on each Ri and Si: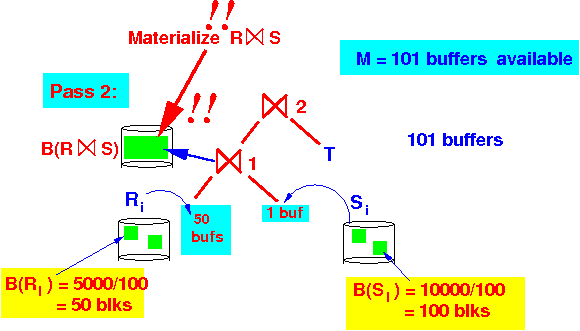 Because B(Ri) = 50 ---> We will only use 50 buffers to index Ri
+ 1 buffer to scan Si
Because B(Ri) = 50 ---> We will only use 50 buffers to index Ri
+ 1 buffer to scan Si
-
We have performed this
check
before:
-
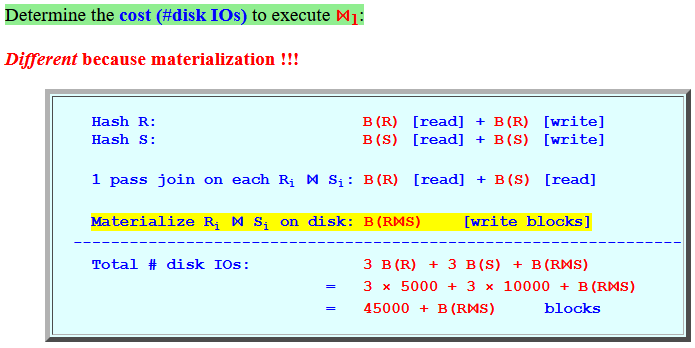
Determine the cost (#disk IOs)
to execute
⋈1:
Different because materialization !!!
Hash R: B(R) [read] + B(R) [write] Hash S: B(S) [read] + B(S) [write] 1 pass join on each Ri ⋈ Si: B(R) [read] + B(S) [read] Materialize Ri ⋈ Si on disk: B(R⋈S) [write blocks] ----------------------------------------------------------------- Total # disk IOs: 3 B(R) + 3 B(S) + B(R⋈S) = 3 × 5000 + 3 × 10000 + B(R⋈S) = 45000 + B(R⋈S) blocks
-
After the
materialization,
all buffers are
available:
(Computing the memory buffer requirement is in fact easier if you materialize... You just "start over" again)
-
Step 3:
determine the best suitable
join algorithm for
⋈2:
- Check if we
use 1-pass
join algorithm for
⋈2:
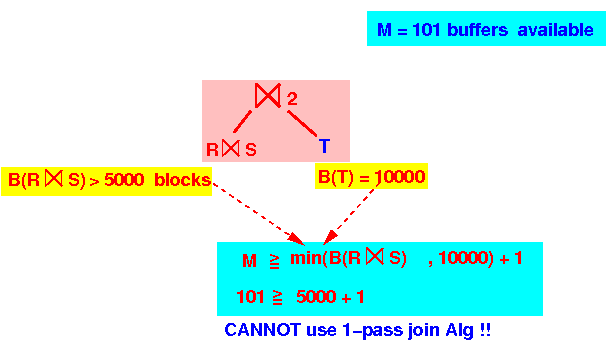
Explanation:
Because both relations are stored on disk, we can use either relation as the first relation !!!
M = 101 B(left relation) = B(R⋈S) > 5000 B(right relation) = 10000 B(smallest) > 5000 for sure !!! 101 < B(smallest) + 1 ====> cannot use one-pass algorithm
- Check if we can
use 2-pass
join algorithm for
⋈2:
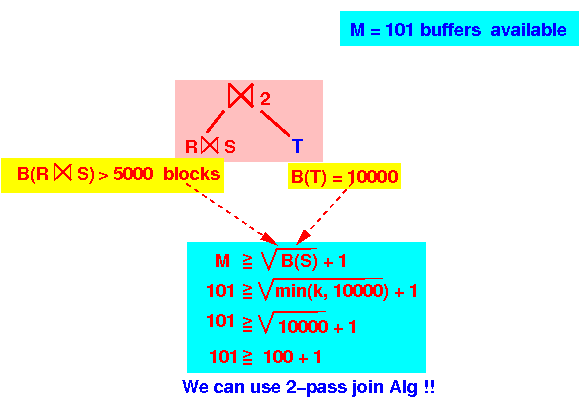
So: use the 2-pass (hash-based) join for ⋈2
- Check if we
use 1-pass
join algorithm for
⋈2:
-
Determine the cost (#disk IOs)
to execute
⋈2:
Hash R ⋈ S: B(R⋈S) [read] + B(R⋈S) [write] Hash T: B(T) [read] + B(T) [write] 1 pass join on each Xi ⋈ Ti: B(R⋈S) [read] + B(T) [read] ----------------------------------------------------------------- Total # disk IOs: 3 × B(R⋈S) + 3 B(T) = 3 × B(R⋈S) + 3 × 10000 = 3 × B(R⋈S) + 30000 blocks
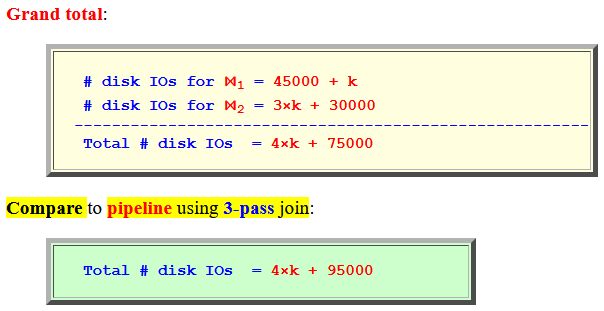
# disk IOs for ⋈1 = 45000 + k # disk IOs for ⋈2 = 3×k + 30000 ------------------------------------------------------- Total # disk IOs = 4×k + 75000 |
Compare to pipeline using 3-pass join:
Total # disk IOs = 4×k + 95000 |
- Pipelining is
not always the
best method !!!
- When pipelining requires the use of multi-pass algorithm, you must consider materialization as an alternative to find the optimal physical query plan
|
|