- OpenMP is a portable, parallel programming model
for shared memory multiprocessor architectures,
developed in collaboration with a number of computer vendors.
- OpenMP API are available for C/C++
and Fortran
- For more information on the OpenMP developer community, including tutorials and other resources, see their web site at: http://www.openmp.org
- OpenMP programs are
Fortran or C/C++ proograms
that include
compiler instructions ("directives")
to tell the Fortran or C/C++ compiler
to generate
parallel execution code
(using threads)
-
Syntax of OpenMP compiler directive for
C/C++:
- Program statements between the { and } are executed by multiple threads
#include <omp.h> #pragma omp parallel [Options...] { ... ... Parallel region ... ... Program statements between the braces ... are executed in parallel by all threads ... }
- The number of threads
that will be created to
execute parallel sections
in an OpenMP program
is controlled by
the
environment variable
OMP_NUM_THREADS
- To set
this
environment variable
use:
export OMP_NUM_THREADS=... Example: export OMP_NUM_THREADS=8
- C/C++
- Compile:
CC -O -c -xopenmp Prog.C
- Link:
CC -O -o Executable -xopenmp Prog1.o Prog2.o ....
- Compile:
- Parallel "Hello World" OpenMP program:
#include <opm.h> int main(int argc, char *argv[]) { #pragma omp parallel { cout << "Hello World !!!" << endl; } }
- Example Program:
(Demo above code)

- Prog file (OpenMP Hello World): click here
- Compile with:
-
CC -xopenmp openMP01.C
- Run with:
export OMP_NUM_THREADS=8
a.outYou will see "Hello World !!!" printed EIGHT times !!! (Remove the #pragma line and you get ONE line)....
- Execution of a parallel section in an OpenMP program:
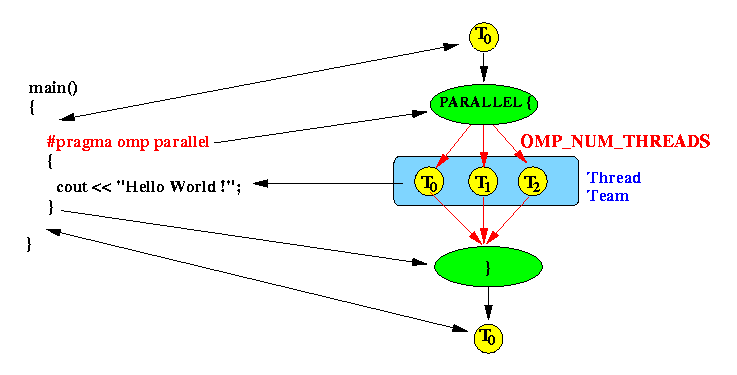
Execution:
- Before the
directive
#pragma omp parallel ,
the program is
single-threaded
This (single) thread is also known as the master thread
- The
directive #pragma omp parallel
tells the compiler to create a
thread team.
The number of threads in the team is determined by the environment variable OMP_NUM_THREADS
- At the end of the parallel section,
ALL threads
are
implicitly joined
(i.e., the master thread calls "pthread_join" on all worker threads)
Then the master thread T0 continue with the single-threaded execution following the PARALLEL section.
- Before the
directive
#pragma omp parallel ,
the program is
single-threaded
- So in essence, an OpenMP program is nothing more than a multi-threaded program that you have seen when we discussed pthreads
- As in Pthreads,
variables
in
OpenMP
can be shared and non-shared (private):
- Shared variables:
-
There is a
single copy
of the variable
and all threads
access that copy
- Private variables:
-
There is one copy
of the variable
for each thread
Each thread accesses its own copy of that variable.
- Shared variables:
- Deafult variable sharing rules
- Variables
without any directives
defined outside the scope of a parallel region
and are accessible
inside the parallel region
are
by default shared
Example:
int N; // Shared #pragma omp parallel { .... N is shared by all threads... } - Variables
without any directives
defined inside the scope of a parallel region
are
by default non-shared (private)
Example:
#pragma omp parallel { int N; // Non-shared (private) .... N is not shared... } - Variables
defined as
private
are
by default non-shared (private)
Example:
#pragma omp parallel private(N) { (It is as if a local variable N is defined) .... N is not shared... }
- Variables
without any directives
defined outside the scope of a parallel region
and are accessible
inside the parallel region
are
by default shared
- Example of SHARED variable:
-
Example Program:
(Shared variable in OpenMP) ---
click here
- Compile with: CC -xopenmp openMP02a.C
- Run with: export OMP_NUM_THREADS=8; a.out (make sure you run on compute.mathcs.emory.edu - an 8-way multi-processor)
You should see the value for N at the end is not always 1009, it could be less. You have seen this phenomenon before in threaded programs when multiple-threads update a shared variable concurrently... The same things is happening here.
#include <omp.h> int main(int argc, char *argv[]) { int N; // Variable defined OUTSIDE parallel region.... // It is therefore SHARED N = 1001; cout << "Before parallel section: N = " << N << endl; #pragma omp parallel { N = N + 1; cout << "Inside parallel section: N = " << N << endl; } cout << "After parallel section: N = " << N << endl; }
-
Example Program:
(Shared variable in OpenMP) ---
click here
- Example of NON-SHARED (private) variable:
-
Example Program:
(Shared variable in OpenMP) ---
click here
- Compile with: CC -xopenmp openMP02b.C
- Run with: export OMP_NUM_THREADS=8; a.out (make sure you run on compute.mathcs.emory.edu - an 8-way multi-processor)
You should see the value for N at the end is always 1002
#include <omp.h> int main(int argc, char *argv[]) { #pragma omp parallel { int N; // Variable defined INSIDE parallel region.... // It is therefore NON-SHARED N = 1001; N = N + 1; } // ERROR if you try to do this: // cout << "N = " << N << endl; // because N is not defined in the outer scope !!! }
-
Example Program:
(Shared variable in OpenMP) ---
click here
- Alternative way to define PRIVATE variables:
-
Example Program:
(Shared variable in OpenMP) ---
click here
- Compile with: CC -xopenmp openMP02c.C
- Run with: export OMP_NUM_THREADS=8; a.out (make sure you run on compute.mathcs.emory.edu - an 8-way multi-processor)
You should see the value for N inside the parallel section is always 1
The variable N outside the parallel section remains 1001
#include <omp.h> int main(int argc, char *argv[]) { int N; // Line XXX N = 1001; cout << "Before parallel section: N = " << N << endl; #pragma omp parallel private(N) { // Define a local variable N ! N = N + 1; // This N is different from the N at line XXX !!! cout << "Inside parallel section: N = " << N << endl; } cout << "After parallel section: N = " << N << endl; } -
Example Program:
(Shared variable in OpenMP) ---
click here
- In addition to compiler directives (pragmas),
there are a number of
support functions
in OpenMP:
Function Name Effect omp_set_num_threads(int nthread) Set size of thread team INTEGER omp_get_num_threads() return size of thread team INTEGER omp_get_max_threads() return max size of thread team (typically equal to the number of processors INTEGER omp_get_thread_num() return thread ID of the thread that calls this function INTEGER omp_get_num_procs() return number of processors LOGICAL omp_in_parallel() return TRUE if currently in a PARALLEL segment omp_init_lock(omp_lock_t *lock) Initialize the mutex lock "lock" omp_set_lock(omp_lock_t *lock) Lock the mutex lock "lock" omp_unset_lock(omp_lock_t *lock) Unlock the mutex lock "lock" omp_test_lock(omp_lock_t *lock) Return true if the mutex lock "lock" is locked, returns false otherwise NOTE: We will study other synchronization primitives and will not discuss omp..lock()
- Example: using
omp_get_thread_num()
#include <iostream.h> #include <omp.h> // Read in OpenMP function prototypes int main(int argc, char *argv[]) { int nthreads, myid; #pragma omp parallel private (nthreads, myid) { /* Every thread does this */ myid = omp_get_thread_num(); cout << "Hello I am thread " << myid << endl; /* Only thread 0 does this */ if (myid == 0) { nthreads = omp_get_num_threads(); cout << "Number of threads = " << nthreads << endl; } } return 0; }
- Example Program:
(Demo above code)
- Prog file: click here
- Compile using the following command:
- CC -xopenmp hello.C
- We will write an
OpenMP program to
find the minimum value
in an array
- The structure of the program is as follows:
/* Shared Variables */ double x[1000000]; // Must be SHARED (accessed by worker threads !!) int start[100]; // Contain starting array index of each thread double min[100]; // Contain the minimum found by each thread int num_threads; int main(...) { for (i = 0; i < MAX; i++) x[i] = random()/(double)1147483648; // ---------------------------- Start parallel ----- #pragma omp parallel { ... Thread i finds its minimum and ... store the result in min[i] } // ---------------------------- End parallel ----- // ---------------------------------------- // Post processing: Find actual minimum // ---------------------------------------- my_min = min[0]; for (i = 1; i < num_threads; i++) if ( min[i] < my_min ) my_min = min[i]; }
- Division of labor scheme:
(For simplicity of discussion, I used 2 threads)
- Split the array into 2 (approximate) equal halfs
- Thread 1 finds the minimum in the first half of the array
- Thread 2 finds the minimum in the second half of the array
- Main thread waits for the results and find the actual minimum.
- Split the array into 2 (approximate) equal halfs
- Graphically:
start[0] start[1] | | | values handled by | values handled by V thread 0 V thread 1 |<--------------------->|<--------------------->|
- The code of the parallel region
is as follows:
#define MAX 1000000 /* Shared Variables */ double x[MAX]; // Must be SHARED (accessed by worker threads !!) int start[100]; // Contain starting array index of each thread double min[100]; // Contain the minimum found by each thread int num_threads; int main(...) { for (i = 0; i < MAX; i++) x[i] = random()/(double)1147483648; // ---------------------------- Start parallel ----- #pragma omp parallel { int id; int i, n, start, stop; double my_min; n = MAX/omp_get_num_threads(); // step = MAX/number of threads. id = omp_get_thread_num(); // id is one of 0, 1, ..., (num_threads-1) /* ---------------------------- Find the starting index ---------------------------- */ start = id * n; /* ---------------------------- Find the stopping index ---------------------------- */ if ( id != (num_threads-1) ) { stop = start + n; } else { stop = MAX; } /* ------------------------------------------ Find the min between x[start] and x[stop] ------------------------------------------ */ my_min = x[start]; for (i = start+1; i < stop; i++ ) { if ( x[i] < my_min ) my_min = x[i]; } /* ---------------------------- Save result in shared area ---------------------------- */ min[id] = my_min; // Store result in min[id] } // ---------------------------- End parallel ----- // ---------------------------------------- // Post processing: Find actual minimum // ---------------------------------------- my_min = min[0]; for (i = 1; i < num_threads; i++) if ( min[i] < my_min ) my_min = min[i]; } - Example Program:
(Demo above code)
- Prog file: click here
Compile with:
-
CC -O -xopenmp openMP-min.C
Run with (on compute):
export OMP_NUM_THREADS=8
a.out
- There are a number of synchronization methods in OpenMP,
but for this short intro
I will limit to the most commonly used one: mutual exclusion.
- Mutual exclusive access
can be achieved in OpenMP
using the
"critical" pragma:
#pragma omp critical { ... ... Mutual exclusive access to ... shared variables ... }
- Example:
int N; // Global - shared by all threads int main(...) { .... /* ------------------- Parallel section ------------------- */ #pragma omp parallel { .... /* --------------------------------------- Section with mutual exclussive access --------------------------------------- */ #pragma omp critical { N = N + 1; } .... } ... }
- A sequential program
that computes an estimate of Pi by integrating
2.0 / sqrt(1 - x*x):
- Example Program:
(Demo above code)
- Prog file: click here
Compile with:
-
CC -O compute_pi.C
Run the program with:
-
a.out NumberOfIntervals
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int i; int N; double sum; double x, w; N = ...; // accuracy of the approximation w = 1.0/N; sum = 0.0; for (i = 1; i <= N; i = i + 1) { x = w*(i - 0.5); sum = sum + w*f(x); } cout << sum; }
- Example Program:
(Demo above code)
- Parallel program design:
division of labor:
values handled by thread 0 | | | | | | | | | | | | | | V V V V V V V V V V V V V V |-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-|-| ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ ^ | | | | | | | | | | | | | | values handled by thread 1 - Parallel program design:
synchronization requirements
- Variable
sum
is
shared
- So updates to sum must be synchronized
- Variable
sum
is
shared
- Version 1 of the OpenMP program to compute Pi:
- Example Program:
(Demo above code)
- Prog file: click here
- Compile with:
- CC -O -xopenmp openMP_compute_pi-1.C
- Run with:
- export OMP_NUM_THREADS=8
- a.out 50000000
Change OMP_NUM_THREADS and see the difference in performance
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int N; double x, w; double sum; // Shared variable, updated ! N = ...; // accuracy of the approximation w = 1.0/N; sum = 0.0; #pragma omp parallel { int i, num_threads; // Non-shared variables !!! double x; num_threads = omp_get_num_threads() ; for (i = omp_get_thread_num(); i < N; i = i + num_threads) { x = w*(i + 0.5); #pragma omp critical { sum = sum + w*f(x); } } } cout << sum; }
- Example Program:
(Demo above code)
- Problem with the first version:
- The CRITICAL
pragma is
INSIDE
the for-loop
- Result: there are
too many synchronizations operations !!!
Performance will suffer....
- The CRITICAL
pragma is
INSIDE
the for-loop
- To eliminate synchronizations, we use private (non-shared) variables
- Improved Version of the OpenMP program to compute Pi:
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int N; double sum; // Shared variable ! double x, w; N = ...; // accuracy of the approximation w = 1.0/N; sum = 0.0; #pragma omp parallel { int i, num_threads; double x; double mypi; // Private variable to reduce synchronization num_threads = omp_get_num_threads() ; mypi = 0.0; for (i = omp_get_thread_num(); i < N; i = i + num_threads) { x = w*(i + 0.5); mypi = mypi + w*f(x); // No synchronization needed ! } #pragma omp critical { sum = sum + mypi; // Synchronize outside loop ! } } cout << sum; }
- Example Program:
(Demo above code)
- Prog file: click here
- Compile with:
-
CC -O -xopenmp openMP_compute_pi-2.C
- Run with:
- export OMP_NUM_THREADS=8
- a.out 50000000
Change OMP_NUM_THREADS ` and see the difference in performance
- The
PARALLEL
is one of several parallel constructs
in
OpenMP
- Here is a list of all
parallel constructions
in OpenMP:
- PARALLEL (section) - discussed
- PARALLEL LOOP (for-loop)
- General work-sharing (Fortran only)
- I will only discuss the PARALLEL LOOP construct because numerical programs usually use for-loops (instead of while-loops)
- The syntax of the
PARALLEL LOOP
construct:
#pragma omp for [parameters] for-statement // Parallel Loop - Meaning
- distribute the
iterations of the for-loop
among the threads.
- Each iteration of the for-loop is executed exactly once (by some thread; you don't need to know by which one).
- distribute the
iterations of the for-loop
among the threads.
- NOTES:
- The loop-index variable
of the
PARALLEL LOOP
construct is
private (non-shared)
- The PARALLEL LOOP construct must appear within a PARALLEL region !!!
- The loop-index variable
of the
PARALLEL LOOP
construct is
private (non-shared)
- Example:
double f(double a) { return( 2.0 / sqrt(1 - a*a) ); } int main(int argc, char *argv[]) { int N; double sum; // Shared variable, updated ! double x, w; N = ...; // accuracy of the approximation w = 1.0/N; sum = 0.0; #pragma omp parallel { int i; double x; double mypi; // Non-shared within the parallel section mypi = 0.0; /* -------------------------- PARALLEL FOR construct -------------------------- */ #pragma omp for for (i = 0; i < N; i = i + 1) { x = w*(i + 0.5); // Save us the trouble of dividing mypi = mypi + w*f(x); // the work up... } #pragma omp critical { sum = sum + mypi; } } cout << sum; }Comment:
- The PARALLEL LOOP
construct grately
simplifies the
parallel program
- It is no longer your problem to divide the labor - the compiler does it for you !
- The PARALLEL LOOP
construct grately
simplifies the
parallel program
- Example Program:
(Demo above code)
- Prog file: click here
- Compile with:
-
CC -xopenmp openMP_compute_pi-3.C
- Run with:
export OMP_NUM_THREADS=8
a.out 50000000Change OMP_NUM_THREADS and see the difference in performance
The division of labor (splitting the work of a for-loop) in a parallel for-loop can be done automatically in OpenMP through the PARALLEL LOOP construct.
- The stack size
of each thread can be controlled by setting
another environment variable:
setenv STACKSIZE nBytes
- For more information on OpenMP, see: http://www.openmp.org