CUDA implementation of the
odd-even sort algorithm
We will create N threads, one thread per array element:
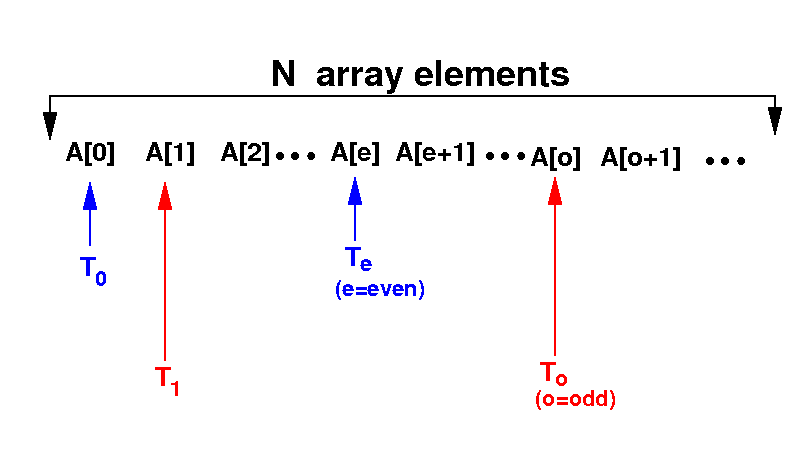
The threads will repeat the sorting steps until the variable isSorted == 1
CUDA implementation of the
odd-even sort algorithm
The even numbered threads will start first:

Thread e compares
A[e] with
A[e+1] and
swap them if
they are out of order
And: sets
isSorted=0
CUDA implementation of the
odd-even sort algorithm
The odd numbered threads will run next:

Thread o compares
A[o] with
A[o+1] and
swap them if
they are out of order
And: sets
isSorted=0
The CUDA odd-even sort algorithm -
CPU part
The CPU code: (1) allocate arrays and (2) then launches the threads (using a <<< 1,N >>> grid):
int main(int argc, char *argv[])
{
int N = Input array size
}
|
N will be specified by the user input
The CUDA odd-even sort algorithm -
CPU part
We define the reference variables to help us allocate the shared arrays:
int main(int argc, char *argv[])
{
int N = Input array size
int *A;
}
|
(This is CUDA syntax... i.e, how CUDA provide the dynamic shared array to us)
The CUDA odd-even sort algorithm -
CPU part
Allocate the 3 shared vectors (as 1-dim arrays):
int main(int argc, char *argv[])
{
int N = Input array size
int *A;
/* =======================================
Allocate a shared array
======================================= */
cudaMallocManaged(&A, N*sizeof(float));
// initialize array A (code omitted)
}
|
(This is CUDA syntax... i.e, how CUDA provide the dynamic shared array to us)
The CUDA odd-even sort algorithm -
CPU part
Launch (at least) N threads as a <<< 1,N >>> grid to perform the odd-even sort:
int main(int argc, char *argv[])
{
int N = Input array size
int *A;
/* =======================================
Allocate 3 shared matrices (as arrays)
======================================= */
cudaMallocManaged(&A, N*sizeof(float));
// initialize array A (code omitted)
oddEvenSort<<< 1, N >>>(A, N); // Using > 1 block can result in error !
// The reason will need to be explained later...
}
|
We will write the kernel code for vectorAdd( ) next...
The CUDA odd-even sort algorithm -
GPU part
First, make each thread computes its own unique ID i:
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( !isSorted )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // Odd phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
The CUDA odd-even sort algorithm -
GPU part
Repeat the sort step (compare and swap) until the array is sorted:
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
SORT step
if ( i%2 == 1 && i < n-1 ) // Odd phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
The CUDA odd-even sort algorithm -
GPU part
Assume that the array is sorted (isSorted is updated to 0 if we need to swap):
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // Odd phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
The CUDA odd-even sort algorithm -
GPU part
Even phase: allow only the "even" threads to do the compare and swap step:
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // Odd phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
The CUDA odd-even sort algorithm -
GPU part
Even phase: make sure that all threads are finished before moving onwards:
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // Odd phase
{
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
The CUDA odd-even sort algorithm -
GPU part
Odd phase: allow only the "odd" threads to do the compare and swap step:
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // odd phase (test is exec'ed by ALL threads)
{ // ONLY an "odd" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
The CUDA odd-even sort algorithm -
GPU part
Odd phase: make sure that all threads are finished before moving onwards:
__global__ void oddEvenSort(int *a, int n)
{
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // odd phase (test is exec'ed by ALL threads)
{ // ONLY an "odd" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
Failed DEMO: /home/cs355001/demo/CUDA/7-sort/odd-even.cu
Problem:
the variable
isSorted is
a local variable
(not shared...)
Local variables are "private" variables for a thread:
__global__ void oddEvenSort(int *a, int n)
{ // EACH thread has its own copy of local variables
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID for each thread
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // odd phase (test is exec'ed by ALL threads)
{ // ONLY an "odd" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0;
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
Problem:
the variable
isSorted is
a local variable
(not shared...)
When thread i updates isSorted, the isSorted variable in other threads are not changed:
__global__ void oddEvenSort(int *a, int n)
{ // EACH thread has its own copy of local variables
int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0; // Thread i will ONLY update its copy !!
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // odd phase (test is exec'ed by ALL threads)
{ // ONLY an "odd" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0; // Thread i will ONLY update its copy !!
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
Solution:
we must make
all threads use (share)
the same variable
isSorted
Recall that each stream multi-processor in the GPU has a shared memory:
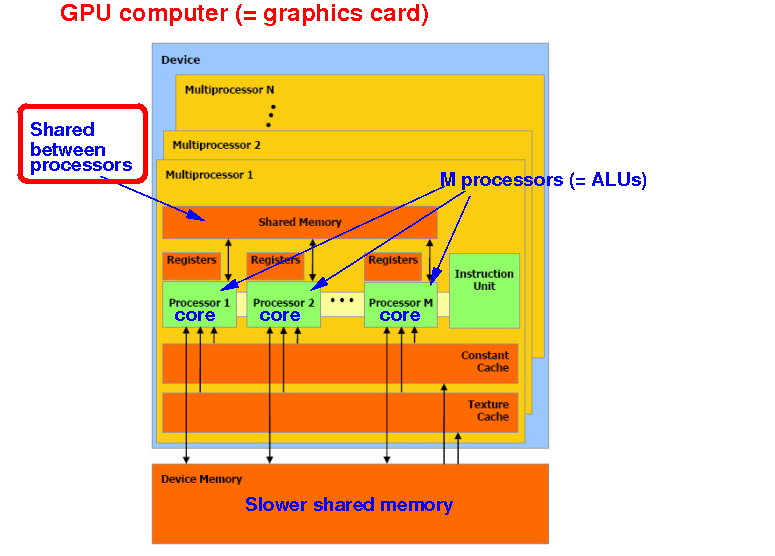
Variables stored in the shared memory will be shared between all threads running on the same multi-processor (= in the same thread block)
Solution:
we must make
all threads use (share)
the same variable
isSorted
The keyword __shared__ will allocate a variable in the shared memory:
__global__ void oddEvenSort(int *a, int n)
{ // EACH thread will share the variable isSorted
__shared__ int isSorted;
int i = blockIdx.x*blockDim.x + threadIdx.x; // Unique ID
isSorted = 0;
while ( isSorted == 0 )
{
isSorted = 1;
if ( i%2 == 0 && i < n-1 ) // Even phase (test is exec'ed by ALL threads)
{ // ONLY an "even" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0; // ALL threads will see this update !!
}
}
__syncthreads(); // All threads must finish before move on
if ( i%2 == 1 && i < n-1 ) // odd phase (test is exec'ed by ALL threads)
{ // ONLY an "odd" thread execute this if-statement
if (a[i] > a[i+1])
{
SWAP(a[i], a[i+1]);
isSorted = 0; // ALL threads will see this update !!
}
}
__syncthreads(); // All threads must finish before move on
}
}
|
DEMO: /home/cs355001/demo/CUDA/7-sort/odd-even.cu
__shared__ variables
are shared among threads
in the same thread block
|
DEMO: demo/CUDA/8-shared-vars/shared_var.cu
__shared__ variables
are shared among threads
in the same thread block
|
DEMO: demo/CUDA/8-shared-vars/shared_var2.cu