Project Overview
Protecting privacy of human subjects while enabling large-scale analysis
of clinical health data is a key challenge in health research.
Current de-identification or microdata (i.e. original records) release
approaches are subject to various re-identification and disclosure risks
and do not provide sufficient protection for our patients. A complementary
approach is to release statistical macrodata (i.e. derived statistics),
which can also be used to construct synthetic data that mimic the original
data.
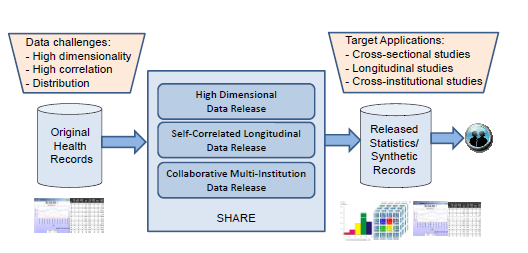
This project propose to develop new methodologies for Statistical Health information RElease (abbreviated SHARE) for anonymizing and sharing health information with differential privacy. Differential privacy is one of the strongest provable privacy guarantees for statistical data release. Given a set of original health records, SHARE releases a set of pre-computed summary statistics with differential privacy, or an optional set of synthetic records that is consistent with the statistics, using which various data mining tasks may be conducted. Current thrusts include: