Project Overview
Health informatics is receiving a tremendous amount of attention nationally and locally, as a strategic area of technological development in the 21st century.
Recent provisions of standardization of health care transactions will make it faster and easier to share health information. However, such data sharing has been stymied by restrictions of the privacy, security and quality of the data.
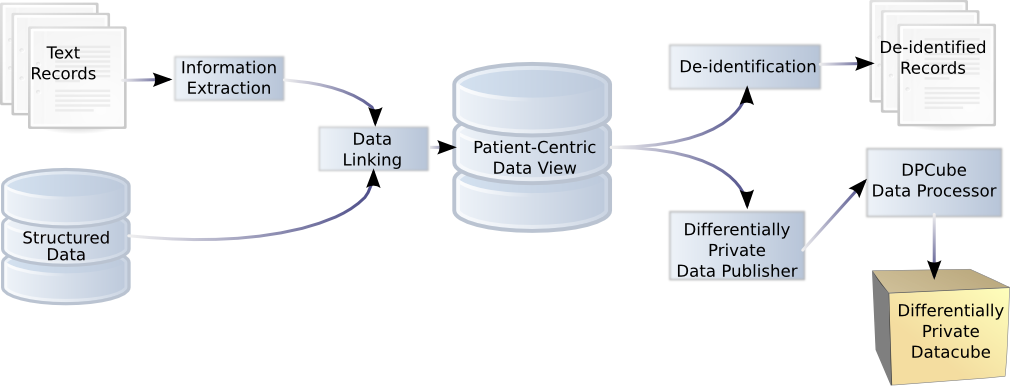
The HIDE project aims to develop a configurable and integrated Health Information DE-identification (HIDE™) framework for publishing and sharing health data while preserving data privacy. Current research thrusts include:
The outcome of the project includes a suite of algorithms and techniques as well as a set of open source software tools that will allow medical information service providers as well as computer science researchers to manage and share privacy constrained data more effectively and efficiently. While the project is focused on the health domain, the algorithms and techniques are widely applicable in various application domains.
Acknowledgement
This research is supported partially by a Career Enhancement Fellowship by Woodrow Wilson Foundation, IBM faculty innovation award, and University Research Committee, ITSC, and CCI at Emory.
Any opinions, findings, and conclusions or recommendations expressed in the project material are those of the authors and do not necessarily reflect the views of the sponsors.